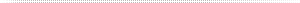When you hear “water treatment” what is the first thing that comes to mind? Sewer water treatment? Certainly this is often the case. Municipal water treatment is classic water treatment requiring aeration, agitation and continuous fluid movement.
The object of this article is to look at some very typical industrial water treatment processes and various compressed air and energy savings projects that have worked well for our clients over the years. The basic fundamentals with regard to compressed air usage are similar to municipal water treatment – a good starting point.
Wastewater Municipal Water & Sewage Treatment:
- Compressed air used for agitation to keep solids in suspension
- Compressed air is often needed to supply oxygen support to the processing bacteria
Air pressure required depends on:
- Liquid/slurry depth
- Actual water head pressure 2.31 feet equals 1 psig
- For estimating we use .5 psig per foot of head of H2O -- specific gravity of water is 1.0. Mixtures and slurries with higher specific gravity will have greater head pressure
Disclaimer: This data is not intended to be complete enough to select wastewater air. It is designed to give the reader an overall view of the basic operating parameters of each type.
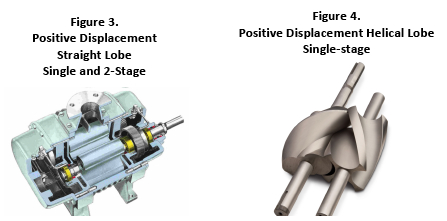
There are many types of blowers (rotary vane, liquid ring, etc.) used in industry, particularly in the smaller sizes. As in most air and gas compression equipment, larger, well applied central units may well prove to be the most energy efficient solution when conditions dictate. Each opportunity needs a specific evaluation.
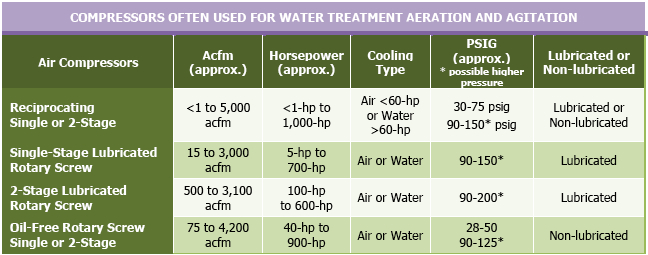
** Larger units are available
** Note: With single-stage centrifugal blowers the ability to deliver higher pressures increases with the flow volume. The required horsepower to produce the flow varies with flow and pressure selection. The air “mass flow” units and the driving power is a direct function of the mass flow or weight of the air.
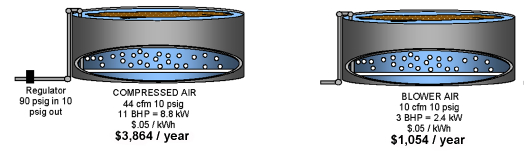
The lower the pressure the lower the energy cost per scfm of delivered volume of compressed air with the same type and class of compressed air operating equipment. This is generally true regardless of the type of compressed air generating unit as long as the pressure flow is within a given units operating parameters.

This looks somewhat simple – just identify the minimum acceptable pressure that works and the required or current actual compressed air flow being used. Then, select the appropriate blower or air compressor. In an existing plant or operation this can often be challenging since many operators do not have nor know this information.
In the field you can measure the flow and inlet pressure, but to accurately estimate the probable lowest usable discharge pressure you will need to know the specific gravity of the solution and the overall height of the liquid or slurry material (depth) to establish the “head pressure” to be overcome.
Unlike a municipal sanitary sewer wastewater treatment facility this data is often not only not readily available but also may well vary over time and application in the industrial wastewater environment.
Generally compressed air is combined with some type of liquid or slurry pump appropriate to handle the material. Often this is an air operated double diaphragm pump due to its simple design and versatile application parameters. They are also relatively quick to repair and/or change. Electric driven pumps are often not even considered.
There are three primary uses of compressed air in all wastewater treatment applications:
- Aeration to supply the processing bacteria with oxygen support
- Agitation to keep the solids in suspension and,
- A continuous, driving pump to move the material.
Basic Methods of Aeration / Agitation
When aeration is required for the oxygen supply then the choices are somewhat limited. The compressed air economic opportunities are:
- Investigate the savings if an electric pump can replace the air driven pump. The primary limiting factors to economic use of an electric in lieu of air driven is the head pressure required (viscosity and depth) and make up of the material.
 |
||
Sandpiper AODD microprocessor stroke optimizer. Courtesy of airvantagepump.com |
- If an air operated double diaphragm pump is the proper selection, identify the lowest effective inlet pressure and add an electronic stroke optimizer. These controls can reduce the air use 40 to 50%, delivering the same throughput while incorporating automatic starts/stop if applicable.
- Identify the proper pressure and flow to select the most effective compressed air supply as described earlier.
When aeration is not needed for the oxygen content and the compressed air is used (with or a process pump) primarily for agitation, additional opportunities exist to deliver the same agitation results at a lower energy cost. Even though compressed air power is very expensive, these other actions should always be carefully evaluated on specific case by case conditions to establish an accurate operation energy cost.
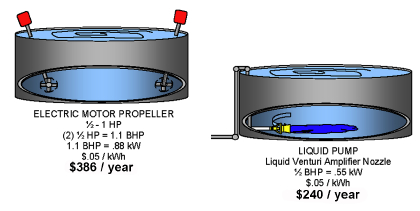
The following case studies cover some of the most prevalent opportunities.
Liquid Flow Eductors
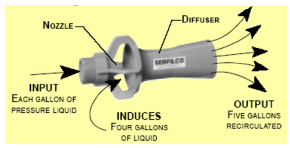
How They Work: Liquid pumped into the eductor nozzles exits at high velocity, drawing an additional flow of the surrounding solution through the educator. This additional flow (induced liquid) mixes with the pumped solution and multiplies its volume five-fold. The source of the pumped liquid (input) can be a pump or filter chamber discharge.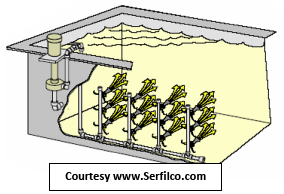
- Eductor agitation delivers five times the pump output at each nozzle. This effectively helps deliver the required level of agitation to critical areas.
- When appropriate and properly engineered and installed, this can often supply proper agitation at lower energy input.
Refinery application to replace agitation air with Liquid Flow Eductor
Example: The caustic production utilized two 40’ tall tanks with 15’ depth. Measured air flow was 240 scfm to both wastewater holding tank. The air was delivered through three 3/4" lines on three sides blowing air to keep the solids off the inside walls. There is also a 20-hp pump that continually circulates the mixture to keep the solids off the bottom and in suspension.
Total energy applied:
240 scfm at 4 scfm input hp 60-hp
Electric motor driven pump 20-hp
Total energy 80-hp
(80 x .746 ÷ .90 @ \$.06 kWh / 8,760 hrs yr) 66.3 kW
Estimated annual current electrical energy cost \$34,847/yr
Project implemented: Install three eductor patterns at appropriate points on the tank walls and a double set on the bottom. Total energy input 10-hp/8 kW centrifugal pump (duplex)
Total electric power operational savings (kW) 54.3 kW
Estimated annual total electric energy savings ($.06 kWh / 8,760 hrs/yr) $28,540/yr
Total project cost (with installation) $20,000
Simple payback 8.4 months
The new eductor system held the solids in suspension as required allowing appropriate storage time between cleaning and clearing.
Steel processing plant filter press running on AODD during complete four hour cycle
The filter runs a 4-hr cycle. A 30-minute final press requires 150’ of head pressure at end of each cycle. Prior to the final press, head pressure is 30 to 40 feet for 3.5 hour per cycle.
Efficiency measures such as this are taught in the Compressed Air Challenge’s® Fundamentals and Advanced Management seminars.
The project was to install a 2-hp electric motor driven centrifugal pump to operate the press the first 3.5 hours of the 4-hour cycle. The production processes is 24 hours a day, 7 days a week, 365 days a year with a blended power rate of \$.10 kWh
Current air flow to 2” AODD 80 scfm
80 scfm at 90 psig at estimated input power (20-hp x .746 ÷ .90) 16.6 kW
Estimated annual electrical energy cost (16.6 kW x \$.10 kWh x 8,760) $14,542/yr
Modified operation
16.6 kW (x 1,095 hours (12% 8,760) x \$.10 kWh $1,817.70/yr
1.7 kW (2-hp motor) x 7,665 hrs/yr x \$.10 kWh $1,303.05/yr
Total estimated annual operating air $3,120.75/yr
Total savings \$11,421.25/yr
Total project cost $5,000
Simple payback 5.3 months
Chlorine Plant: Two 40’ tall wastewater final stage polishing tanks before release to groundwater (fluid depth 30 feet)
Current use measured 220 scfm at 90 psig compressed air regulated to 15 psig to supply agitation to maintain clarity. The air is delivered to the bottom of each tank from which it bubbles up through the water.
Current estimated electric power to produce the 220 scfm @ 4 cfm/input 55-hp
Current estimated electric power x .746 ÷ 90 45.6 kW
Operating cost (8,760 hrs @ \$.10 kWh) \$39,945/yr

The first alternate technology considered was utilizing the “liquid flow eductors”. However, the power to handle this tall and wide tank was 75-hp (62 kW) which was obviously not a calculated savings so the idea was abandoned. Supplying the low pressure air at 16 psig with a single-stage helical lobe blower was next explored.
A helical lobe blower using a 25-hp electric motor with 22 bhp power draw (22 x .746 ÷ 90) or 18.2 input kW will deliver 239 scfm at 15 psig. With this, the primary estimated annual energy cost is \$15,944/yr (18.2 x \$.10/kWh x 8,760 hrs) or an annual electrical energy savings of \$24,000/yr. The installed cost of the new blower package and piping was \$14,000 (up to \$28,000 depending on the package) installed. And a anticipated simple payback of 7 to 12 months.
The last case study example is in a steel mill wastewater treatment area where the limestone slurry tank is agitated with a 30-hp progressive Moyno cavity pump in a 12’ tall by 8’ diameter tank. The lime must be effectively kept in suspension to avoid channeling with solids buildup around the pump entry blocking effective agitation. The solids block the recirculation volume, which accelerate the fouling factor and significantly increases the number of expensive cleanings. This can be a significant environmental and time consuming issue to clean out and in all probability also affecting production.
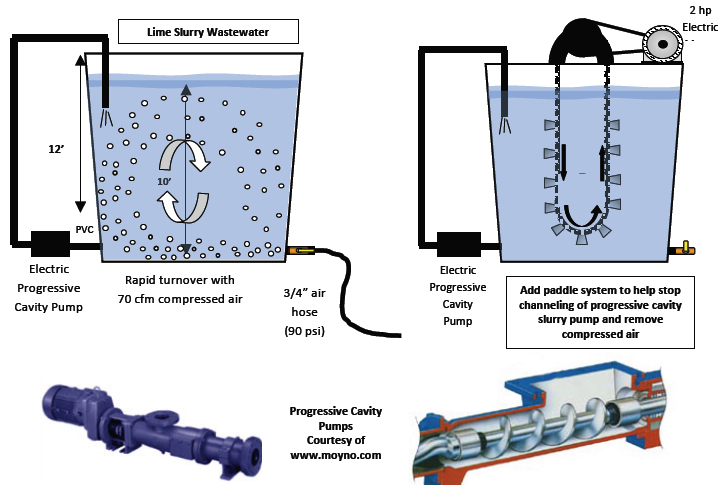
The goal was to keep the solids and in suspension until the regular scheduled maintenance time. Premature fouling was currently avoided by adjusting fluid tank levels as required when maintenance personnel found time. This situation was not only troublesome but could lead to unplanned significant downtime with the current manpower situation.
After the tank was cleared of solids and reset to avoid a reoccurrence, a 3/4" air line at 90 psig entry pressure was opened into the bottom side of the tank. The measured flow was 80 scfm, it did do the job.
Total estimated pump power (30-hp [x .746 ÷ 90]) 24.9 kW
Total air flow 80 scfm (80 ÷ 4 sec/input hp = 20-hp x .746 + .9) 16.6 kW
Total estimated power utilized (8,760 operating hours/yr @ \$.10/kWh) 41.5 kW
Total current estimated electrical operating energy cost \$36,354/yr
A mechanical mixing assist with paddles was added to replace the 1” air line (see drawing on previous page). This arrangement was driven by a 2-hp electric motor (2-hp x .746 ÷ .85) or 1.75 kW. This has proven to be very successful.
New configuration electrical operating energy:
30-hp progressive cavity pump 24.9 kW
Mechanical paddle pump 1.75 kW
Total electrical operating energy power 26.65 kW
Total electrical operating annual energy cost \$23,345/yr
Total electrical energy savings \$13,009/yr
Cost of project \$2,540
Simple payback 2.3 months
Summary
If air is needed for the wastewater treatment process and agitation alone is not enough, then there are really two choices – blower air or air compressor air. The proper choice will have a very positive impact on energy cost and, correctly applied and maintained, should enhance productivity.
The second opportunity in this case is pump selection – electric or air driven. With or without flow enhancers such as eductors, if air operated, the use of microprocessor stroke optimized controls on AODD pumps should be considered.
If only agitation is required, it is usually to keep solids in suspension, then there are a range of options to replace or reduce compressed air usage including such mechanical devices as propellers, paddles, etc.
As you look at your wastewater system, let your imagination be your guide. As they say, “think outside the box”.
For more information please contact Hank Van Ormer, Air Power USA, tel: 740-862-4112, email: [email protected], www.airpowerusainc.com
Table data and figures supplied by:
Spraying Systems Co. -- IL (www.spray.com), Continental Blower -- NY (continentalblower.com), Dearing Air Compressor -- OH (dearingcomp.com), Elmo Rietschle/Gardner Denver -- IL (gd-elmorietschle.com), Monyo Inc. -- OH (Monyo.com), Serfilco Ltd, --IL (Serfilco.com)
September 2011