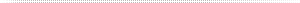Air Operated Double Diaphragm (AODD) Pumps are popular and versatile. Often, they also offer an excellent opportunity to lower the demand for compressed air, especially given the latest advances in controls and the energy savings to be realized.
A Good All-around Pump
It’s not unusual for an operation to have AODD pumps already in place because they there’s a good chance they arrived at the plant from an equipment supplier as part of the package, or someone selected them in the past. Regardless of how they got to the plant, there are number of reasons why they’re widely used in a variety of industries.
For one, they work well as long as they are “big enough.” They also have many desirable operating characteristics compared to some other types of pumps. Specifically, they:
- Can be designed to handle aggressive chemical or physical product throughput.
- Are relatively insensitive to running empty without catastrophic failure.
- Can often be quickly fixed or repaired.
- Automatically adjust to significant head pressure increases as long as the pressure is available and the stroke/min throughput is acceptable.
In summary, this is a very “forgiving design.” Yet the management of compressed air use calls for monitoring and controlling AODD pumps.
Typical Compressed Air Operated and Electric Pump Data
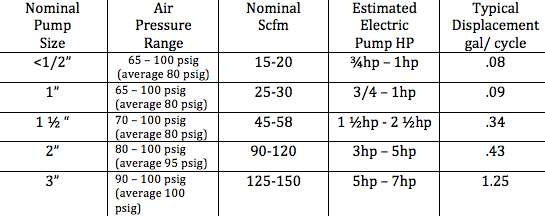
Table 1
This table shows a generic 2 inch AODD pump using 90 to 120 scfm with an average 95 psig inlet pressure. However, the only accurate way to identify compressed air use other than a flow meter is to count the cycles.
If an AODD pump is left uncontrolled several things will occur. Most performance curves are based on a fluid with a specific gravity of 1 (H2O).
- As the fluid increases in viscosity and the head pressure rises the strokes per minute (compressed air used) will fall at the same inlet pressure. If the viscosity is reduced the compressed air use will increase.
- As the strokes per minute increase from 48 str/min to 325 str/min the compressed air use goes from 25 cfm @ (5hp) to 150 cfm @ (35hp) and the throughput from 20 gpm to 140 gpm.
- It is very important to apply the pump at the lowest acceptable str/ min the lowest effective inlet pressure, monitoring these parameters will help to optimize the air demand.
Figure 1
AODD Pump Control is Paramount
While all compressed air-operated equipment should be controlled, it is especially important with AODD pumps.
AODD pumps are reciprocating, positive displacement pumps. The area in which the pumping media is contained consists of an inlet and discharge manifold and two liquid chambers. An air valve alternately directs compressed air behind the diaphragms in the air chambers. Fluid to be pumped is drawn into one liquid chamber from the inlet manifold as a similar fluid is expelled from the other liquid chamber through the discharge manifold during this cycle.
There are a number of advantages to AODD pumps. They do not require electricity, are self-priming, can pump fluids with solids in suspension, and can run dry or be dead-headed without damaging the pump. In addition, they can transfer a wide range of media from wastewater to more vicious substances such as slurries or even cement. However, automatically controlling compressed air use has been a challenge.
Leveraging Inlet Pressure Control
One method of gaining control over compressed air use is by controlling AODD pump inlet pressure. Is the pump running most of the time at the lowest possible pressure? The higher the pressure, the more compressed air is used. Setting a fixed pressure is often somewhat limited in success as conditions may change in product viscosity, or short-term needs for higher pressure, etc., which may require constant adjustment.
Cycle (stroke/min) control is potentially the most effective optimizer available. It controls the cycle to the lowest and proper speed to assure a full transport line of product, while using the least amount of compressed air.
Over the years this has been tested with the use of backpressure regulators, manual controls, etc. One of the basic drawbacks of the method, however, has always been pump efficiency. As the cycles are cut back, it tends to reduce pump efficiency and when conditions change the inefficiency may get worse.
To address the issue, some manufacturers developed modifications to the air distribution system inside the pump. This allows operators to optimize performance at the available pressure by adjusting the inlet passage size until the throughput flow is acceptable. The solution has shown to be effective when feasible.
Consider Electric-Driven Pumps to Achieve Savings
There are good reasons why some choose air-driven AODD pumps, one of which is overall simplicity. Another is because there is no need to run electric power to any given pump. Still another is their ability to withstand a dirty, hostile environment. Yet don’t overlook electric-motor-driven pumps, including diaphragm types, to achieve potential compressed-air savings now or in the future.
As shown in the earlier chart, a 2 inch AODD pump will use an average of 90-120 cfm of compressed air at 95psig or 23 hp to 30 hp of compressed air supply. An electric-driven pump under the same conditions would draw between 3 hp and 5 hp. If the net horsepower savings here is an average of 21 hp, it translates to a savings of \$7,920 per year (x.746/.10 = 16.5kw x \$.06kwh x 8000 hr/y) when an electric-driven pump is used for power rather than compressed air under these conditions.
A word of caution, however: As the head pressure increases the input energy required for the electric-driven pump increases. The stroke/min of the compressed-air driven pump will fall at higher pressure decreasing as long as the available compressed air pressure in the plant is “high enough.”
To manage this, conduct product evaluations with good data input. Under head conditions and acceptable stroke/min, the compressed-air driven pump may actually be more cost effective.

Figure 2
Batch Pumping Versus Continuous Pumping
Does the pump run continuously because it can? Yes, that’s the advantage of an AODD pump. It can run on empty and continue to operate and pump product as it is received. However, as the load falls off, the stroke/min goes up and thus the “highest air use” is at no load. This is often overlooked.
Figure 3 below compares a typical batch pumping system’s annual electrical energy operating cost to that of a continuous pumping system. The projected savings is a very conservative one.
The annual batch operation cost is driven by:
- The batch pump always running at full load (lowest possible compressed air demand without controls).
- Running the batch pump only 10% of the time as shown here from an actual plant compressed air system evaluation. The level switch trips and shuts off the compressed air supply to the pump when it is not needed.
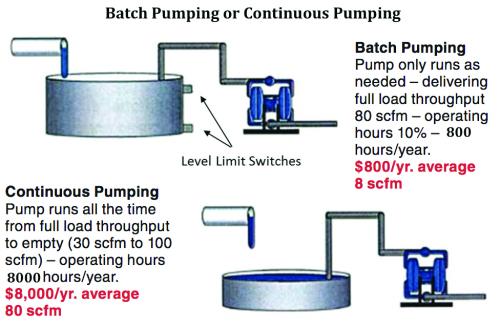
Figure 3
Using a 2 inch AODD pump continuously running with an average demand of 80 scfm and the batch also at 80 scfm shows a cost of about \$8,000/ year without the batch control and \$800/ year with the batch control. This is calculated an annual electrical energy cost of \$0.06 kWh at 8000 hours per year.
Controlling the batch pump operation will always yield savings if it can be implemented. Before assuming there is no budget to modify the system, be sure to know the true cost in recoverable energy cost.
Using Microprocessors to Control Efficiency
It is most important is to realize that in any air operated pump operation, monitoring and control of the inlet pressure and cycles is critical to compressed air use management. In all, 80 – 85% of the AODD pumps found in our compressed air system audits are uncontrolled.
Recently, there have been various microprocessor-based, AODD cycle/stroke control systems introduced which have proven to be very effective. Most utilize a special high-volume, high-speed (35 milliseconds to open / 35 milliseconds to close) air-piloted dispensing valve.
This dispensing valve is controlled by a microprocessor, which analyzes the stroke frequency and throughput flow characteristics to determine the proper and lowest cycle rate to optimize the throughput. Once established it then shuts off the air supply during the stroke and allows product flow and pump inertia to complete the stroke without any additional airflow, it then opens again.
The result is a full flowing line of product without air pockets or voids. The stroke is stopped at the proper point and the pump does not contact the housing as an uncontrolled unit will. This results in longer pump life and lower maintenance costs.
If there is a change in product viscosity the microprocessor will operate several cycles and then readjust itself. It can also be equipped with auto air shutoff when no product is present.
As shown in the table below, several key points are evident:
- At the same input pressure, the compressed air use, stroke, and cycle rate fall 35 – 40% with the control engaged.
- Product throughput per stroke increases the average product flow per scfm significantly (from about 50 – 100%).
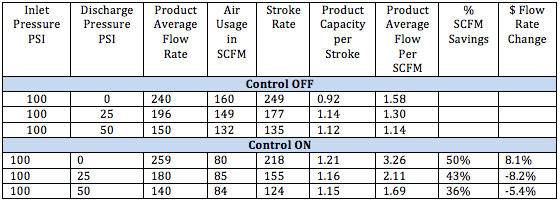
These microprocessor controls have successfully eliminated the compressed air inlet control and pump inefficiency problem of the past by utilizing modern electronics. They should be evaluated on most applications from 1 ½“ class AODD pumps and up, and other conditions that may show an opportunity.
ome are available only as part of the pump assembly and others, such as shown in figure 4, can be mounted on the inlet line to the AODD pump if applicable with the appropriate electric supply.

Summary
Over the years of auditing AODD industrial applications we have found effective compressed air reduction opportunities in 80 – 85% of operations. Many of these are just common sense – don’t pump product any faster than you need to for productivity; don’t over pressure the inlet; and don’t run the pump empty; etc.
However, the availability of microprocessors to create a very responsive control while maintaining effective pump efficiencies has opened up even more opportunities to lower the compressed air use and operating energy costs. They may not be economical for every size, type, and application – but perhaps should often be considered and evaluated.
To read similar System Assessment End Use articles visit www.airbestpractices.com/system-assessments/end-uses.
Read all the articles of this series:
Missed Demand-Side Opportunities Part 1 - Flow Restrictions from Pipe Headers
Missed Demand-Side Opportunities Part 2 - Integrating Multiple Air Compressor Controls
Missed Demand-Side Opportunities Part 3 - Controlling Open Blowing with Compressed Air
Missed - Demand-Side Opportunities Part 7 - The Importance of System Pressure Control